Autoren: Stefan Wimmer und Robert Finger *
Empirische Studien in der Agrarökonomie zur Evaluation von Agrarpolitik nutzen häufig Daten, die aus Datenschutzgründen nicht veröffentlicht werden dürfen. Beispiele sind einzelbetriebliche Buchführungsdaten der Zentralen Auswertung in der Schweiz oder des Farm Accountancy Data Networks (FADN) in der EU. Dies hat zur Folge, dass Studienergebnisse nicht repliziert werden können oder dass nicht transparent nachvollziehbar gemacht werden kann, wie Studienergebnisse zustande kommen. Dies trägt zur „Glaubwürdigkeitskrise“ von empirischer Forschung bei und ist insbesondere dann problematisch, wenn auf Grund einzelner Studien Politikmassnahmen eingeführt, angepasst oder abgeschafft werden.
In einer kürzlich im Journal of Agricultural Economics veröffentlichten Studie (Wimmer and Finger, 2022) evaluierten wir die Eignung synthetischer Daten, den Trade-off zwischen Datenschutz und Forschungstransparenz zu überbrücken. Synthetische Daten sind generierte, ‚künstliche‘ Daten, die die statistische Struktur der Originaldaten bewahren, ohne jedoch eine einzige Beobachtung des Originaldatensatzes zu beinhalten.
Generierung der synthetischen Datensätze
Die Verwendung synthetischer Daten geht auf Rubin (1993) zurück. Synthetische Daten bestehend aus k Variablen können durch Imputationsverfahren allgemein mit den folgenden Schritten erzeugt werden (Faisal, Hutson and Mohammed 2021):

Die Schritte 1–4 können mit einer Vielzahl von Methoden durchgeführt werden. Wir vergleichen zum Beispiel die nichtparametrische Methode der Klassifikations- und Regressionsbäume (engl. classification and regression trees, CART) und eine parametrische Methode unter Verwendung normaler linearer Regressionen unter Beibehaltung der Randverteilung (NORMRANK). Beide Methoden sind im Package synthpop (Nowok, Raab und Dibben 2016) der statistischen Software R implementiert.
Empirische Anwendungen
Wir evaluieren die Eignung der synthetischen Datengenerierung für Anwendungen in der Agrarökonomie und Agrarpolitik anhand einer Reihe produktionsökonomischer Methoden, die sich in ihrer Komplexität unterscheiden. Erstens schätzen wir einfache Produktionsfunktionen mittels der Kleinstquadratmethode, die den betrieblichen Output (z.B. Milchproduktion) anhand der verwendeten Inputs (z.B. Arbeit-, Kapital-, und Materialeinsatz) erklären. Diese Modelle werden zum Beispiel verwendet, um zu analysieren, in welchem Umfang Inputs zur Produktion beitragen. Damit kann beispielsweise abgeschätzt werden, wie eine Einschränkung gewisser Inputs die Produktion beeinflusst. Zweitens schätzen wir die stochastische Produktionsfrontier, in der neben stochastischen Ungenauigkeiten auch technische Ineffizienz zu Differenzen zwischen beobachtetem und maximal möglichem Output führen kann. Drittens schätzen wir die Produktionsfrontier mittels Data Envelopment Analyse (DEA), in der die technische (In-)effizienz eines jeden Betriebes mittels linearer Programmierung ermittelt wird. Produktionsfrontier-Modelle werden oft verwendet, um Verbesserungspotentiale durch Effizienzgewinne aufzuzeigen und zu quantifizieren (z.B. Renner et al. 2021).
Wir wenden die genannten Methoden auf zwei verschiedene Datensätze an. Datensatz 1 umfasst öffentlich verfügbare Produktionsdaten norwegischer Milchviehbetriebe (Kumbhakar, Wang und Horncastle 2015).** Dieser Datensatz umfasst die Jahre 1998-2006 und besteht aus 2729 Betriebsbeobachtungen. Wir betrachten Milch (in Litern pro Jahr und Betrieb) als Output und Land, Arbeit, gekauftes Futter, andere variable Inputs, Viehkapital und sonstiges Kapital als Inputs. Datensatz 2 ist eine Stichprobe von 1684 deutschen Ackerbaubetriebe aus dem EU-FADN für das Jahr 2018. Wir definieren Output als aggregierte Einnahmen aus allen landwirtschaftlichen Produkten, und Inputs bestehen aus Land, Arbeit, Material und Kapital.
Ergebnisse
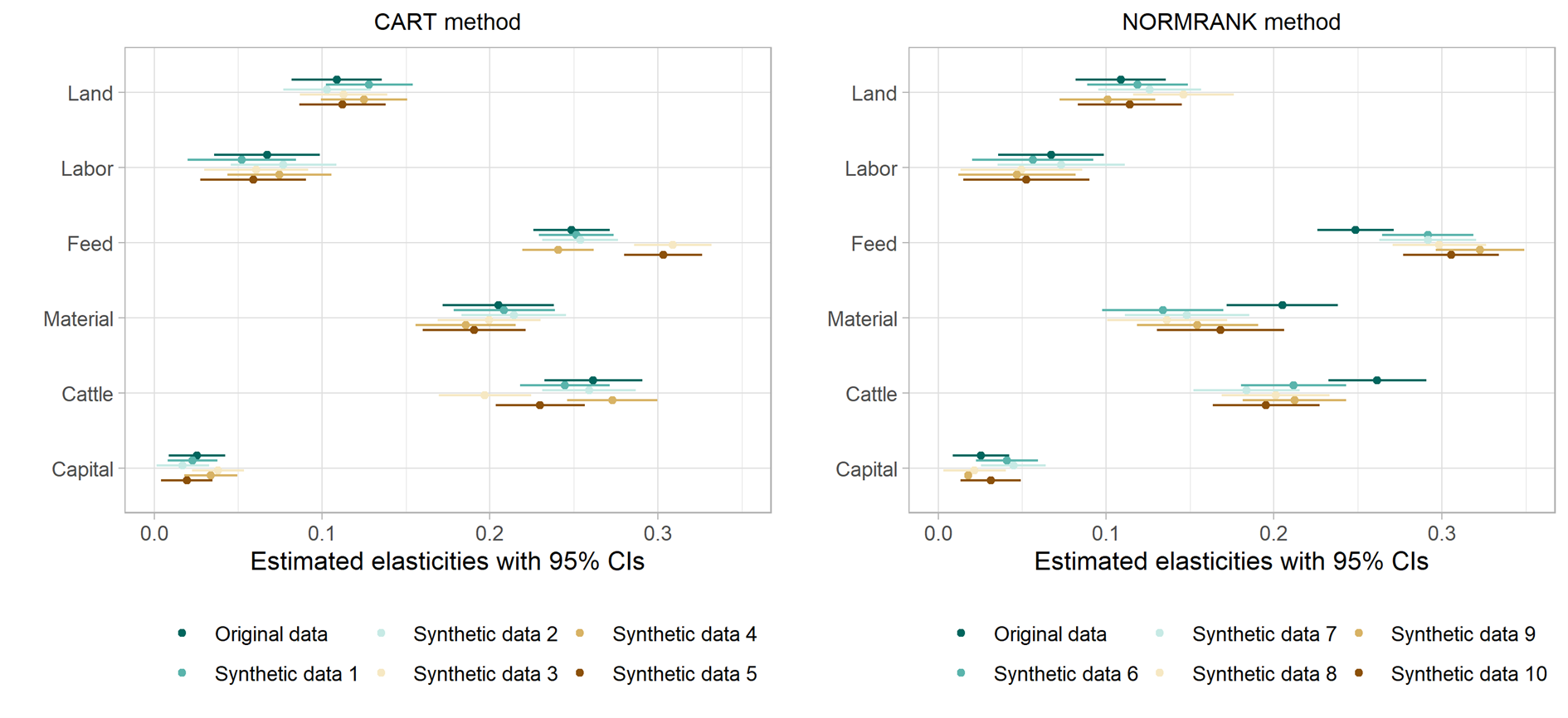
Wir präsentieren hier Ergebnisse für Datensatz 1. Die Ergebnisse zeigen, dass sich insbesondere die CART Methode sehr gut eignet, synthetische Daten für Produktionsanalysen zu generieren. Abbildung 1 stellt exemplarisch die geschätzten Outputelastizitäten für jeweils fünf synthetische Datensätze generiert mit den CART (links) und NORMRANK (rechts) Methoden im Vergleich zu den mit dem Originaldatensatz erhaltenen Ergebnissen dar. Die 95%-Konfidenzintervalle überlappen jeweils sehr stark basierend auf der CART Methode, während die NORMRANK Methode zu grösseren Abweichungen – insbesondere bei den Elastizitäten des Futters, Materials und Viehbestandes – führt.
Abbildung 1: Geschätzte Parameter einer Cobb-Douglas Produktionsfunktion mit 95% Konfidenz-intervallen.
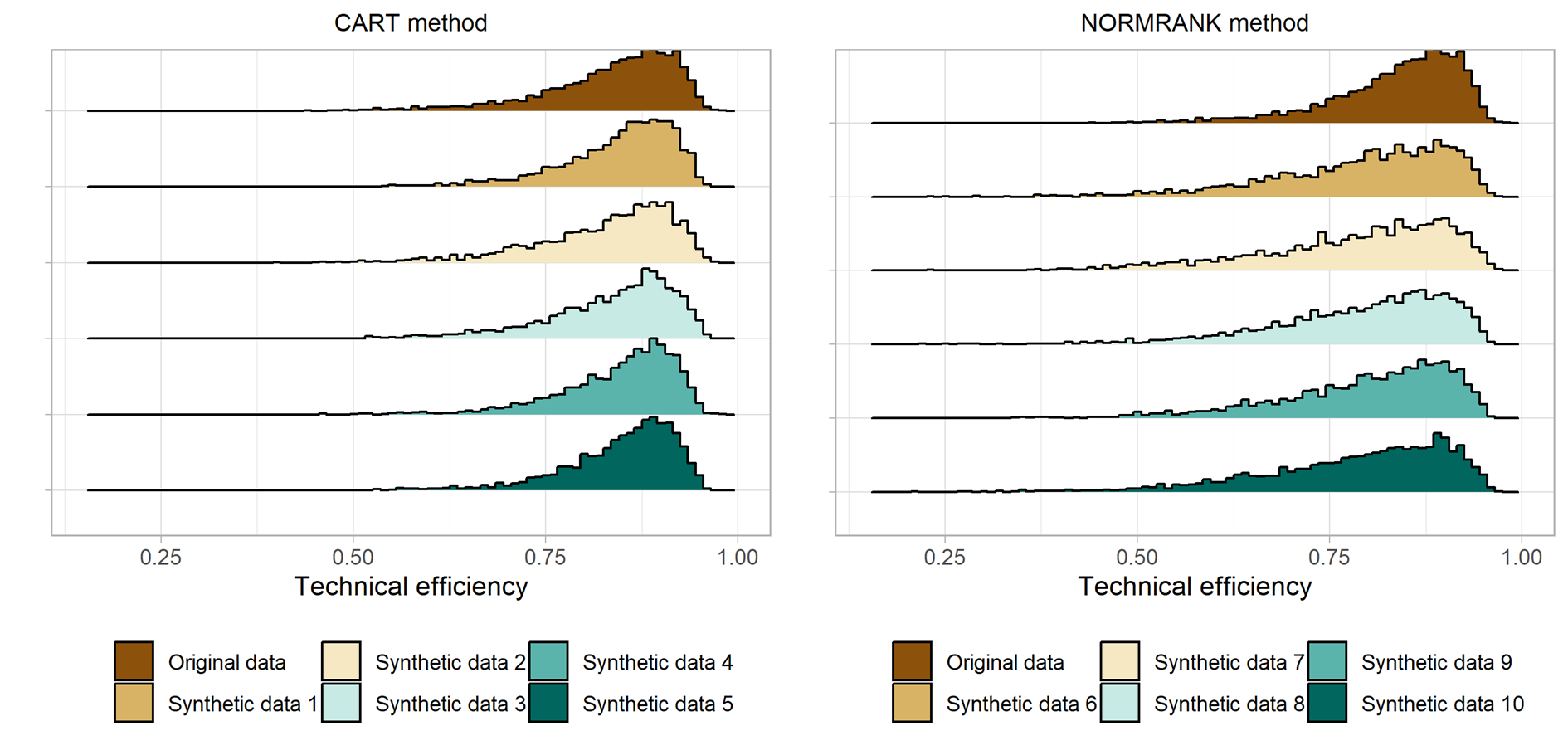
Ein ähnliches Bild zeigt sich hinsichtlich der technischen Effizienzen (siehe Abbildung 2): Der durchschnittliche Wert von 0,84 auf Grundlage der Originaldaten legt nahe, dass landwirtschaftliche Betriebe der Stichprobe ihre Produktion im Durchschnitt um 16 % steigern könnten, ohne den Input-Einsatz zu verändern. Im Vergleich dazu werden Effizienzwerte werden leicht unterschätzt und zeigen höhere Standardabweichungen sowie niedrigere Mindestwerte, wenn die synthetischen Daten mit der NORMRANK-Methode generiert werden. Bei der CART-Methode hingegen ist die Verteilung der TE-Scores sehr ähnlich zu derjenigen, die sich mit den Originaldaten ergibt.
Abbildung 2: Verteilung der technischen Effizienzwerte basierend auf der Cobb-Douglas-Produktionsfrontier.
Die Ergebnisse der Analyse der FADN Daten zeichnen ein ähnliches Bild, jedoch werden die Unterschiede zwischen den beiden Methoden CART und NORMRANK deutlicher (Details siehe Wimmer und Finger, 2022).
Schlussfolgerungen
Unseren Ergebnissen nach eignen sich synthetische Daten insbesondere mittels der CART Methode sehr gut, die Lücke zwischen Datenschutz und Forschungstransparenz zu schliessen. Die Nutzung synthetischer Datensätze sollte daher von Förderorganisationen und politischen Entscheidungsträgern ermöglicht und gefördert werden. Zum Beispiel braucht es einen klaren rechtlichen Rahmen für die Verwendung und Veröffentlichung solcher Daten. Zudem sollten wissenschaftliche Zeitschriften daher ihre Datenrichtlinien anpassen, um die Veröffentlichung synthetischer Daten zu fördern, wenn Originaldaten nicht zur Verfügung gestellt werden dürfen. Dabei erfordern solche Anpassungen die Zustimmung von Datenlieferanten. Der potentielle Nutzen für Landwirtschaft und Agrarpolitik ist gross, da reproduzierbaren Forschungsergebnissen und zuverlässigeren politischen Empfehlungen führen.
Die Veröffentlichung synthetischer Daten birgt jedoch auch einige Risiken, die es zu berücksichtigen gilt. Wir betonen, dass sich unsere Studie auf synthetische Daten zu Replikationszwecken konzentriert und nicht auf die Veröffentlichung origineller Ergebnisse oder die Ableitung von politischen Empfehlungen. Auch darf die Möglichkeit zur Veröffentlichung synthetischer Daten die Veröffentlichung von Originaldaten nicht verhindern. Schliesslich muss vor der Veröffentlichung synthetischer Daten eine systematische Überprüfung des Datenschutzes stattfinden. Weitere Forschung ist zudem notwendig, um die Eignung synthetischer Daten zum Beispiel für Paneldatenmethoden zu bewerten.
Referenzen
Faisal, M., Hutson, G. & Mohammed, M.A. (2021) Synthetic NEWS data. Available at: https://nhs-r-community.github.io/NHSRdatasets/articles/synthetic_news_data.html [Accessed July 25, 2022].
Kumbhakar, S.C., Wang, H.-J. & Horncastle, A.P. (2015) Production, distance, cost, and profit functions. In: A practitioner’s guide to stochastic frontier analysis using Stata. Cambridge: Cambridge University Press, pp. 9–44.
Nowok, B., Raab, G.M. & Dibben, C. (2016) synthpop: Bespoke creation of synthetic data in R. Journal of Statistical Software, 74(1), 1–26.
Renner, S., Sauer, J., & El Benni, N. (2021) Why considering technological heterogeneity is important for evaluating farm performance? European Review of Agricultural Economics, 48(2), 415–445 https://doi.org/10.1093/erae/jbab003
Rubin, D.B. (1993) Discussion: statistical disclosure limitation. Journal of Official Statistics, 9(2), 461–468.
Wimmer, S. & Finger, R. (2022) A note on synthetic data for replication purposes in agricultural economics. Journal of Agricultural Economics. Available at: https://onlinelibrary.wiley.com/doi/full/10.1111/1477-9552.12505
* Stefan Wimmer und Robert Finger sind Mitarbeiter der Gruppe für Agrarökonomie und –politik der ETH Zürich.
** Codes zur Replikation oder Anwendung auf andere Analysen sind öffentlich zugänglich unter: https://github.com/AECP-ETHZ/Synthetic-data-ag-econ
